
Managed MLflow
Contents
Managed MLflow#
Managing the complete machine learning lifecycle#
![]()
What is Managed MLflow?#
Managed MLflow is built on top of MLflow, an open source platform developed by Databricks to help manage the complete machine learning lifecycle with enterprise reliability, security and scale.
Benefits#
Experiment tracking#
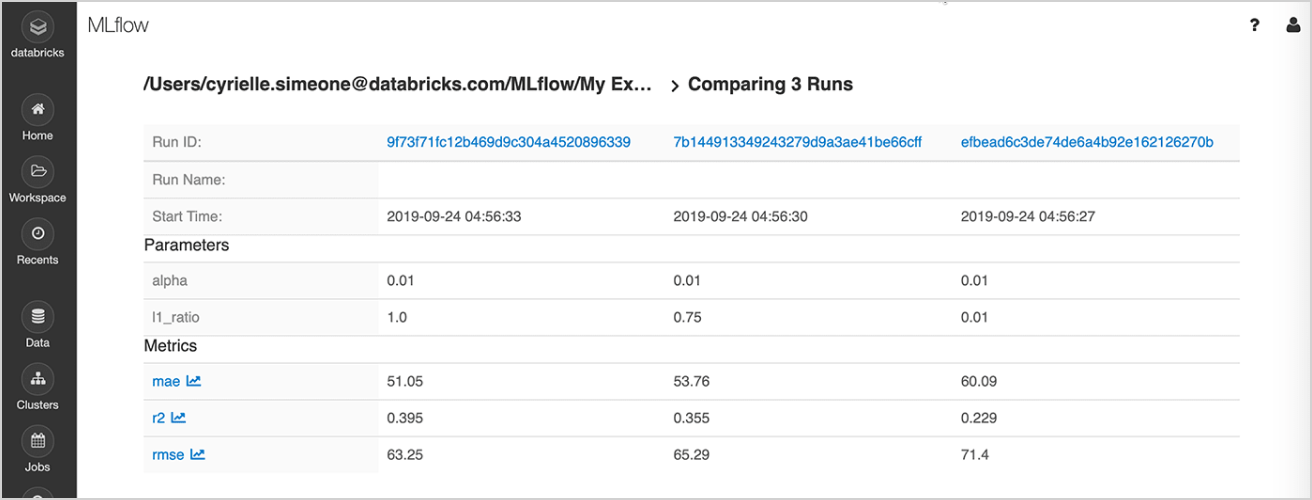
Run experiments with any ML library, framework or language, and automatically keep track of parameters, metrics, code and models from each experiment.
By using MLflow on Databricks, you can securely share, manage and compare experiment results along with corresponding artifacts and code versions — thanks to built-in integrations with the Databricks Workspace and notebooks.
Model management#
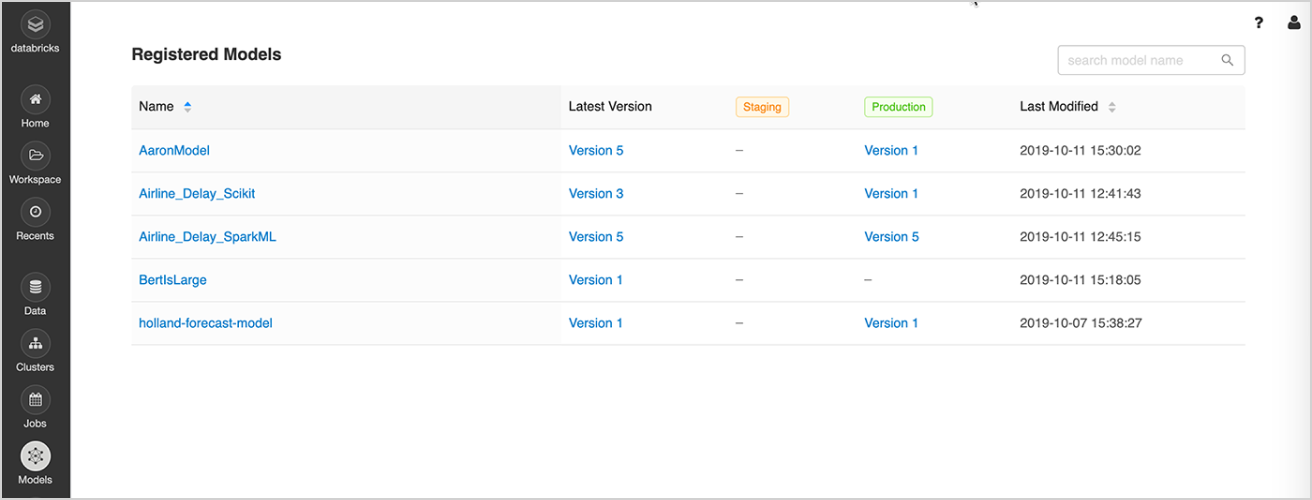
One central place to discover and share ML models, collaborate on moving them from experimentation to online testing and production, integrate with approval and governance workflows and CI/CD pipelines, and monitor ML deployments and their performance.
The MLflow Model Registry facilitates sharing of expertise and knowledge, and helps you stay in control.
Model deployment#
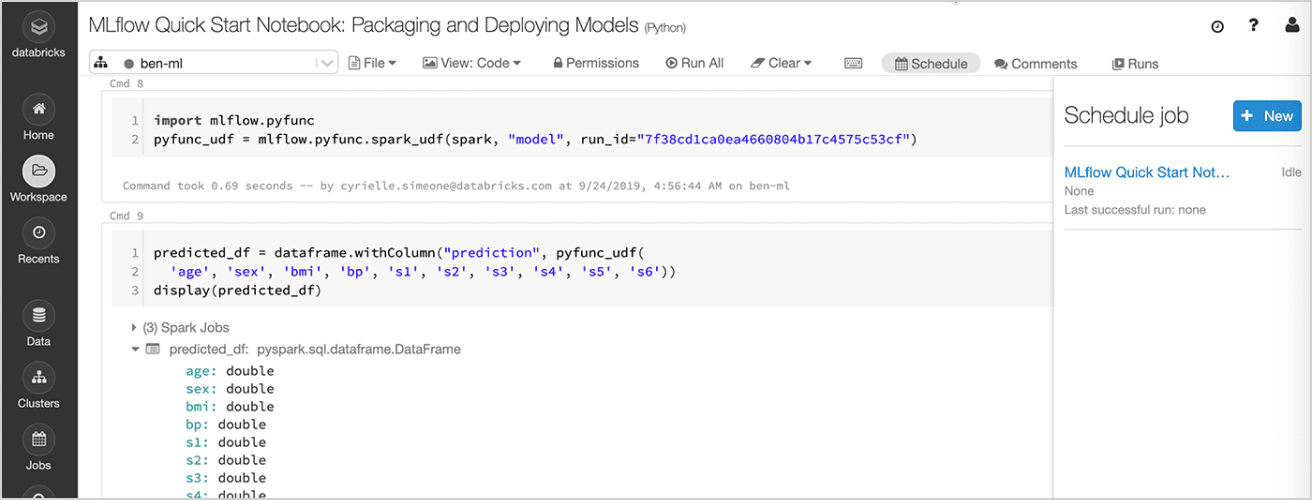
Quickly deploy production models for batch inference on Apache Spark™ or as REST APIs using built-in integration with Docker containers, Azure ML or Amazon SageMaker.
With Managed MLflow on Databricks, you can operationalize and monitor production models using Databricks Jobs Scheduler and auto-managed Clusters to scale based on the business needs.
Features#
MLflow Tracking#
MLFLOW TRACKING: Automatically log parameters, code versions, metrics, and artifacts for each run using Python, REST, R API, and Java API
MLFLOW TRACKING SERVER: Get started quickly with a built-in tracking server to log all runs and experiments in one place. No configuration needed on Databricks.
EXPERIMENT MANAGEMENT: Create, secure, organize, search, and visualize experiments from within the Workspace with access control and search queries.
MLFLOW RUN SIDEBAR: Automatically track runs from within notebooks and capture a snapshot of your notebook for each run, so that you can always go back to previous versions of your code. LOGGING DATA WITH RUNS: Log parameters, data sets, metrics, artifacts and more as runs to local files, to a SQLAlchemy compatible database, or remotely to a tracking server.
DELTA LAKE INTEGRATION: Track large-scale data sets that fed your models with Delta Lake snapshots.
ARTIFACT STORE: Store large files such as S3 buckets, shared NFS file system, and models in Amazon S3, Azure Blob Storage, Google Cloud Storage, SFTP server, NFS, and local file paths.
MLflow Projects#
MLFLOW PROJECTS: MLflow projects allow to specify the software environment that is used to execute your code. MLflow currently supports the following project environments: Conda environment, Docker container environment, and system environment. Any Git repo or local directory can be treated as an MLflow project.
REMOTE EXECUTION MODE: Run MLflow Projects from Git or local sources remotely on Databricks clusters using the Databricks CLI to quickly scale your code.
MLflow Model Registry#
CENTRAL REPOSITORY: Register MLflow models with the MLflow Model Registry. A registered model has a unique name, version, stage, and other metadata.
MODEL VERSIONING: Automatically keep track of versions for registered models when updated.
MODEL STAGE: Assigned preset or custom stages to each model version, like “Staging” and “Production” to represent the lifecycle of a model.
CI/CD WORKFLOW INTEGRATION: Record stage transitions, request, review and approve changes as part of CI/CD pipelines for better control and governance.
MODEL STAGE TRANSITIONS: Record new registration events or changes as activities that automatically log users, changes, and additional metadata such as comments.
MLflow Models#
MLFLOW MODELS: A standard format for packaging machine learning models that can be used in a variety of downstream tools—for example, real-time serving through a REST API or batch inference on Apache Spark.
MODEL CUSTOMIZATION: Use Custom Python Models and Custom Flavors for models from an ML library that is not explicitly supported by MLflow’s built-in flavors.
BUILT-IN MODEL FLAVORS: MLflow provides several standard flavors that might be useful in your applications, like Python and R functions, H20, Keras, MLeap, PyTorch, Scikit-learn, Spark MLlib, TensorFlow, and ONNX.
BUILT-IN DEPLOYMENT TOOLS: Quickly deploy on Databricks via Apache Spark UDF for, a local machine, or several other production environments such as Microsoft Azure ML, Amazon SageMaker, and building Docker Images for Deployment.